7.빅데이터 분석 데이터 시각화 기법과 이해
1. 데이터 시각화의 중요성
개요
- 빅데이터의 가장 큰 특징은 텍스트와 이미지가 비정형성을 갖고 있고, 규모뿐만 아니라 빠르게 전파되기 때문에 패턴을 찾기가 쉽지 않은 특성을 가지고 있다는 것
- 유용한 정보의 증가만큼 불필요한 정보도 급증하시 있어 방대한 데이터 속에서 의미를 찾아내고 분석하는 일이 중요
- 가장 중요한 능력:
데이터를 얻는 능력, 처리하는 능력, 가치를 뽑아내는 능력, 시각화 하는 능력, 전달하는 능력일 것 - 빅데이터는 선형적 구조의 방식 설명 한계가 있기에 데이터 시각화 (Data Visualization)
빅데이터의 2가지 목적: 데이터분석과 의사소통
시각화 인사이트 프로세스
- 데이터 시각화는 그 자체가 목적이 아니며, 결국 데이터로부터 유용한 정보와 인사이트를 얻어내기 위한 과정
통찰과 인사이트(insight)의 사전적 의미
[통찰]
- 예리한 관찰력으로 사물을 훤히 꿰뚫어 봄
- [심리]새로운 사태에 직면했을 때, 과거의 경험에 의존하지 않고 과제와 관련시켜 전체 상황을 다시 파악함으로써 그 과제를 해결하는 것. 문제 해결이나 학습의 한 원리
시각화 인사이트 프로세스 과정
-
문제 정의 및 목표 설정: 분석하고자 하는 문제를 명확하게 정의하고 목표를 설정. 어떤 종류의 정보나 통찰력을 얻고자 하는지를 명확히 이해.
-
데이터 수집 및 전처리: 필요한 데이터를 수집하고 전처리를 수행. 이 단계에서는 데이터의 정확성과 완전성을 확인하고, 필요한 경우 데이터를 정제하거나 결측치를 처리.
-
시각화 디자인: 목표와 데이터의 특성에 맞게 적절한 시각화 기법을 선택. 그래프, 차트, 지도, 다양한 시각화 도구 등을 활용하여 데이터를 효과적으로 표현.
-
시각화 구현: 선택한 시각화 디자인을 구현하고 데이터를 시각적으로 표현. 이 단계에서는 시각화 도구나 프로그래밍 언어를 사용하여 실제 시각화를 생성.
-
인터랙션 추가: 시각화에 상호 작용성을 추가하여 사용자가 데이터를 탐색하고 상세 정보를 확인할 수 있도록 함.
-
시각화 해석: 생성된 시각화를 해석하여 데이터로부터 인사이트를 도출. 패턴, 추세, 이상치 등을 식별하고 의미 있는 정보를 추출.
-
의사 결정 및 전달: 시각화를 통해 얻은 인사이트를 기반으로 의사 결정을 내리고, 필요한 경우 이를 다른 이해관계자와 공유. 시각화 결과물을 보고서나 프레젠테이션 형태로 전달하여 다양한 이해관계자들이 이해하고 활용할 수 있도록 함.
-
피드백 및 개선: 최종 결과물에 대한 피드백을 수집하고, 필요한 경우 시각화를 개선하거나 추가 분석을 수행. 지속적인 피드백과 개선을 통해 시각화 프로세스를 최적화.
2. 정보 시각화
개요
대부분의 시각화 도구에는 다양한 차트와 그래프 지원 적절한 데이터와 정보 시각화를 위한 수단으로 사용
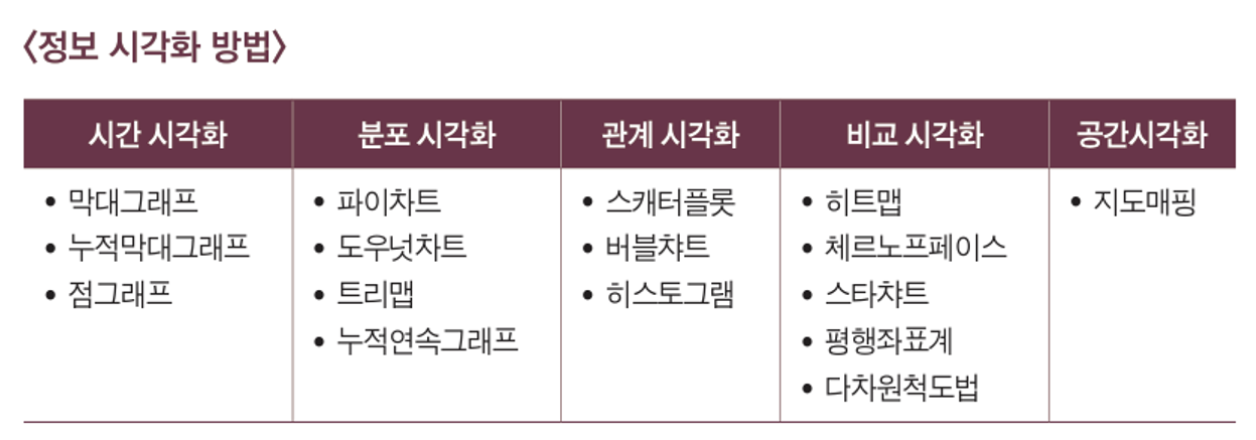
시간 시각화
- 시간에 따른 데이터는 변화를 표현,
시계열 데이터의 가장 특징적인 요소는 트렌드, 즉 경향성으로 장기간에 걸쳐 진행되는 변화 또는 트렌드를 추적하는데 사용 - 시간 데이터는
분절형과연속형으로 나눌 수 있으며, 분절형은 데이터의 특징 시점 또는 특정 시간 구간 값으로 나타냄. 기온변화 같은 데이터는 연속형
1) 막대그래프
- 가로는 시간 순서대로 정렬된 시간의 특징 시점. 세로는 그래프의 범위. 수치를 길이로 표현해 절대값을 갖는 동일한 폭의 막대를 동일한 간격으로 배치, 여러 값의 상대적인 차이를 한눈에 알아 봄
- 막대 값들의 차이가 미미하거나 표시할 값의 수가 많은 경우, 막대들을 비교하기 쉽지 않음. 이 경우 시각적 차이를 강조하기 위해 막대의 다양한 색상을 적용할 수 있다 이때 색상은 특정 상태나 범위 따위를 나타냄.
- 모든 막대가 동일한 범위나 상태에 있는 경우에는 색상이 불필요. 색상의 일관성을 유지하거나 아예 색상을 사용하지 않는 것이 오히려 시각적으로 도움
2) 누적 막대 그래프
- 누적 막대그래프의 구성은 일반적인 막대그래프와 거의 비슷. 단 하나의 차이점이라면 한 구간에 해당하는 막대가 누적된다는 점 뿐
3) 점 그래프
4) 연결된 점 또는 선 그래프
분포 시각화
1) 원그래프
2) 도넛차트
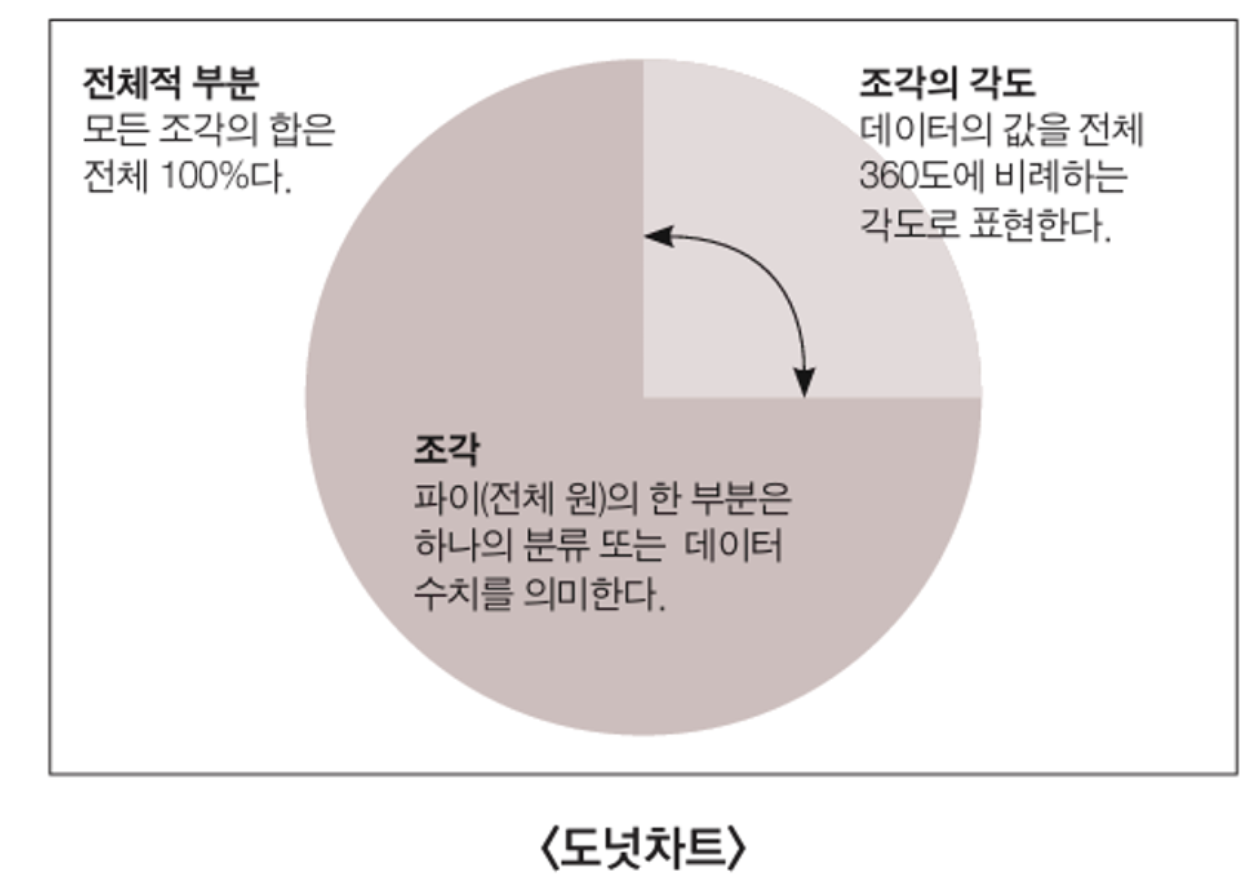
3) 트리맵
- 트리맵은
영역기반의 시각화로, 각 사각형의 크기가 수치를 나타냄. 한 사각형을 포함하고 있는 바깥의 영역은 그 사각형의 포함된 대 분류를, 내부의 사각형은 내부적인 세부 분류를 의미 - 트리맵은 단순 분류별 분포 시각화에도 사용하지만, 위계 구조가 있는 데이터나 트리 구조의 데이터를 표시할 때 활용

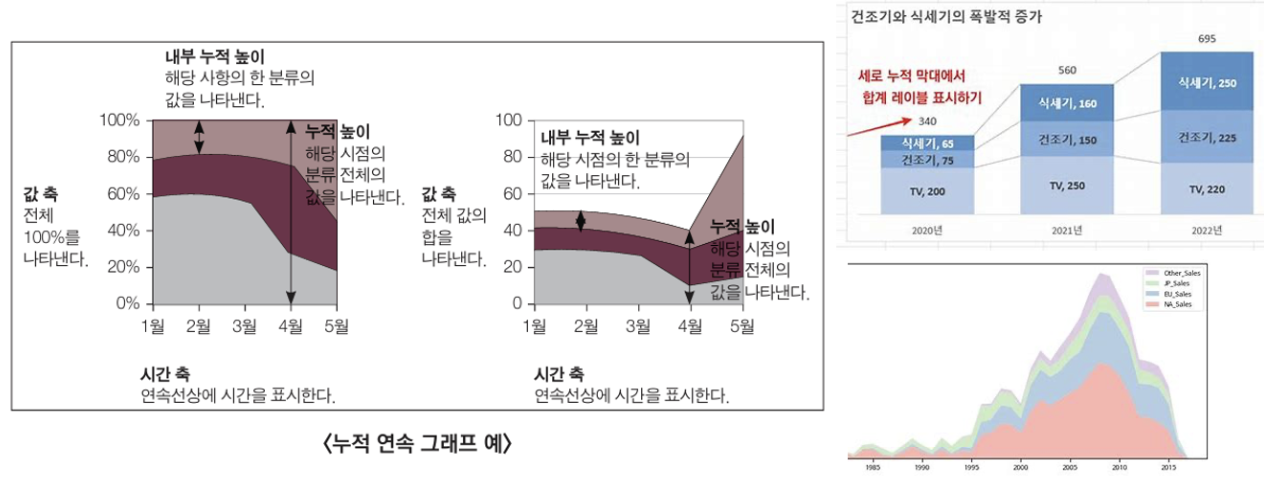
4) 누적 연속 그래프
- 몇 개의 시계열 그래프를 차곡차곡 쌓아 올려 그려 빈 공간을 채워가는 것
- 가로축은 시간, 세로축은 데이터 값
- 누적 영역그래프에서 한 시점의 세로 단면을 가져오면 그 시점의 분포를 볼 수 있음
- 시간에 따른 연속적인 누적 막대그래프
관계 시각화
- 상관관계를 알면 한 수치의 변화를 통해 다른 수치의 변화 예측 가능
- 관계 시각화는
스캐터 플롯과멀티플 스캐터 플롯이 사용 - 스캐터플롯은 시각적인 변화나 두 변수의 관계를 알아볼 때 활용
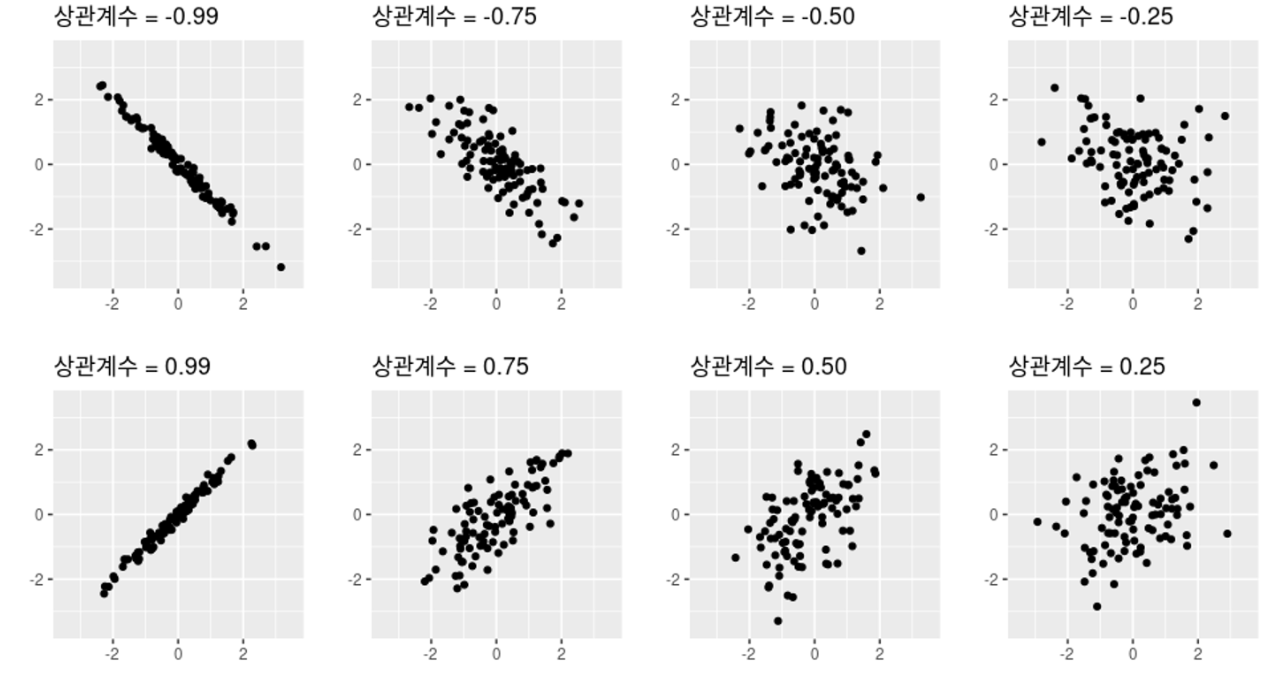
1) 산점도
스태터 플롯또는산점도는 두 데이터 항목의 공통변이를 나타내는 2차원 도표- 가로축과 세로축의 변수값에 대응하는 점을 좌표에 배치하면 그 상관관계를 확인
- 점들이 오른쪽 위로 올라가는 추세면
양의 상관관계, 점이 오른쪽 아래로 떨어지는 추세면음의 상관관계. 만약 점의 패턴이 보이지 않는다면 두 변수 상관관계 X
2) 버블차트 / 3) 히스토그램
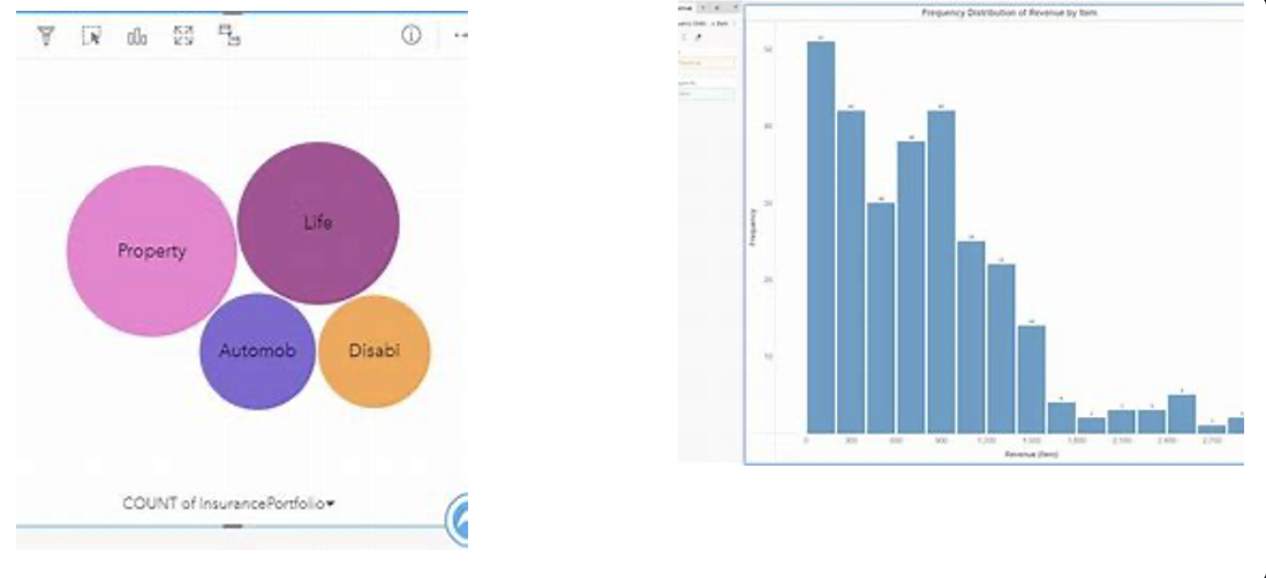
비교 시각화
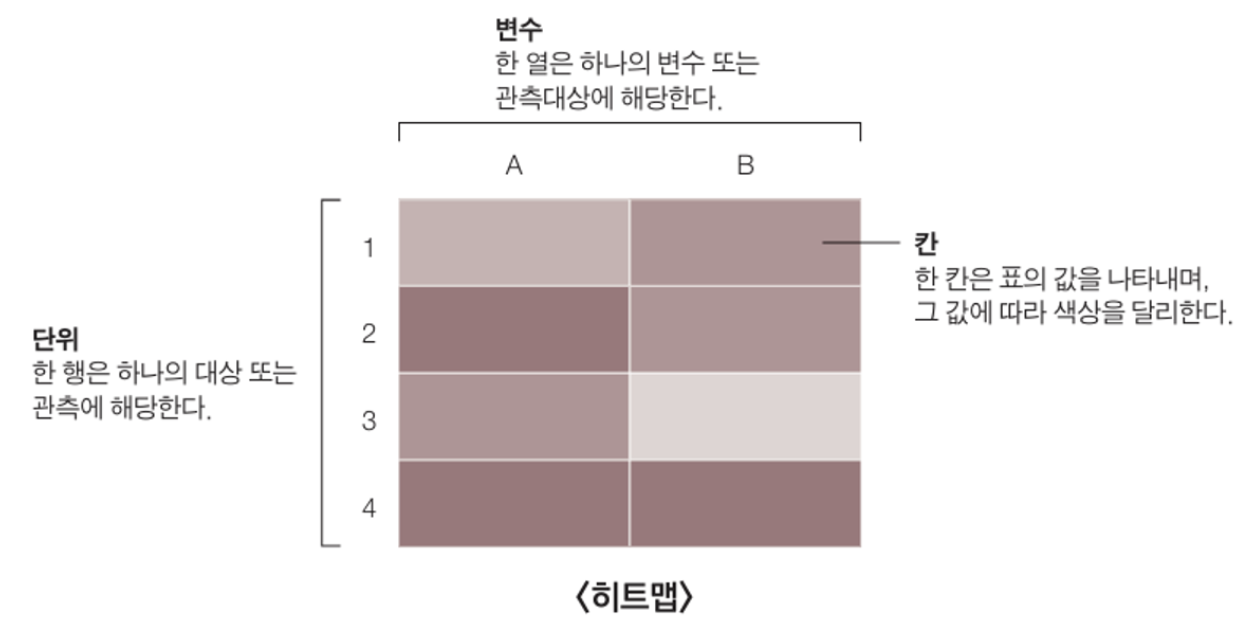
1) 히트맵
시각화 기법에서 가장 많이 유용하게 쓰이는 그래프 중 하나, 한 칸의 색상으로 데이터 값 표현
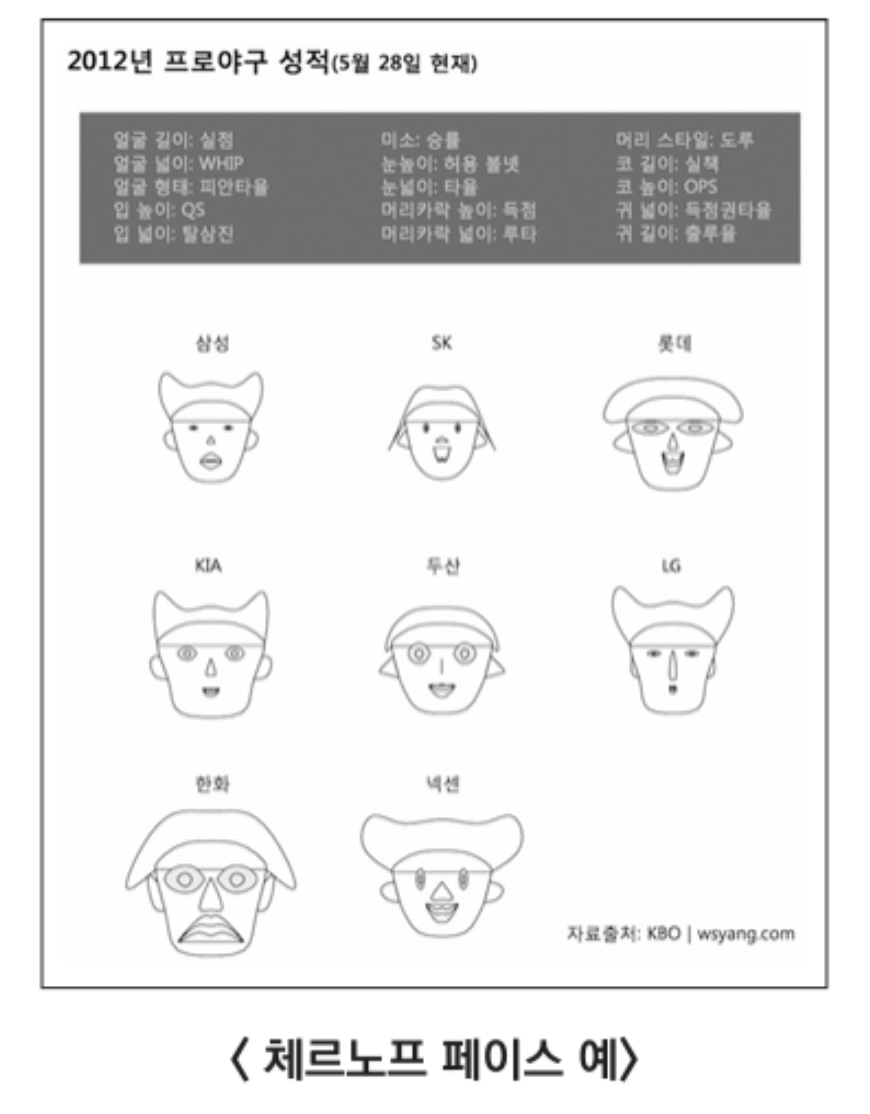
2) 체르노프 페이스
- 체르노프 페이스(Cernoff face) 는 데이터를 사람의 얼굴 이미지로 표현하는 방법
- 얼굴의 가로너비, 세로높이, 눈, 코, 입, 귀 등 각 분위를 변수로 대체
- 데이터의 개별적인 부분에 집중해 그리는 것이 가능
- 엄밀한 의미의 데이터 그래픽에는 포함되지 않고, 보통 사람들에게 혼란을 줄 우려
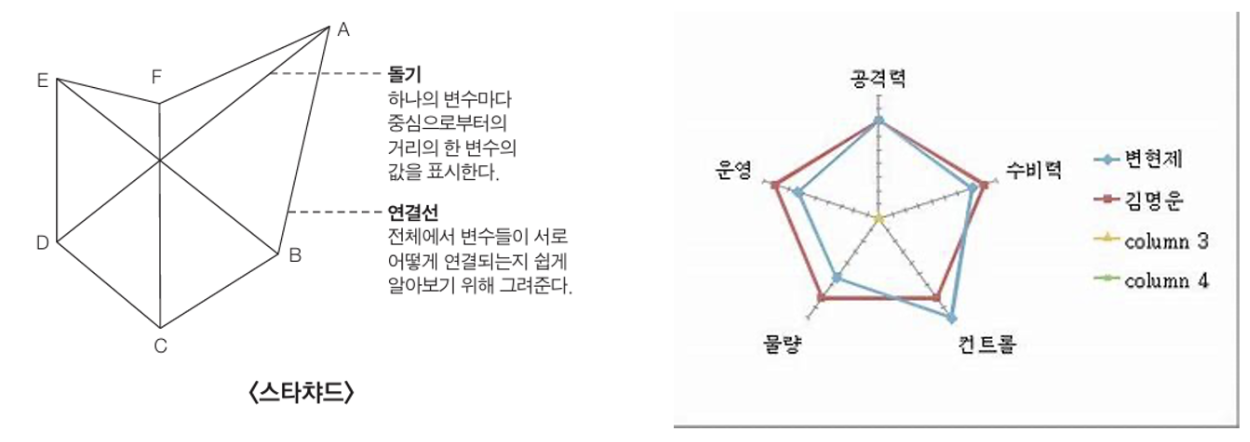
3) 스타차트
- 모양 때문에 거미줄 차트 또는 방사형 차트
- 중앙에서 외부 링까지 이어지는 몇 개의 축을 그리고, 전체 공간에서 하나의 변수마다 축 위의 중앙으로부터의 거리로 수치를 나타냄
- 각 변수를 라인위에 표시한 지점을 연결해 연결선을 그리면 그 결과는 별 모양의 도형으로 나타냄
4) 평행좌표계
- 대상이 많은 데이터에서 집단적인 경향성을 쉽게 알아볼 수 있게 함
- 여러 축을 평행으로 배치, 한 축에서 윗부분은 변수 값 범위의 최대값, 아래로는 변수 값 범위의 최소값을 나타냄
- 측정 대상은 변수 값에 따라 위아래로 이어지는 연결선으로 그림
3. R을 이용한 시각화 구현
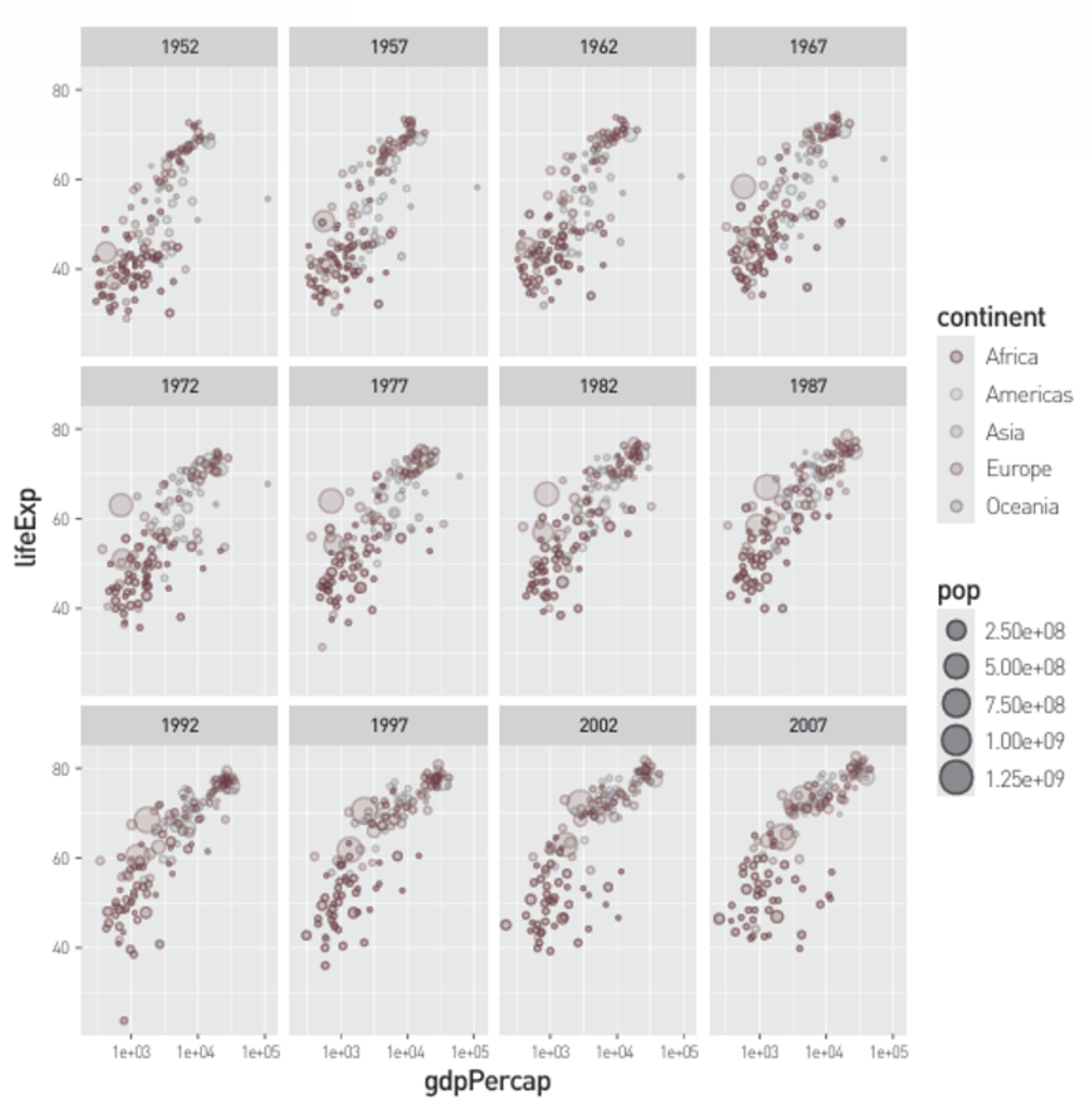
시각화를 통한 데이터의 직관적 이해
시각화 데이터 gapminder data의 구성 항목
| 열 변수명 | 변수형 | 내용 |
|---|---|---|
| country | 142개 레벨의 범주형 | 국가명 |
| continent | 5개 레벨의 범주형 | 국가가 속한 대륙 |
| year | int | 1952~2007(5년단위) |
| lifeExp | num | 기대수명 |
| pop | int | 인구 |
| gdpPercap | num | 1인당 국내총생산 |
실습을 위한 사전 준비
R, R-Studio 설치 해보기
댓글남기기