6.빅데이터 분석 비정형 데이터분석
1. 텍스트마이닝
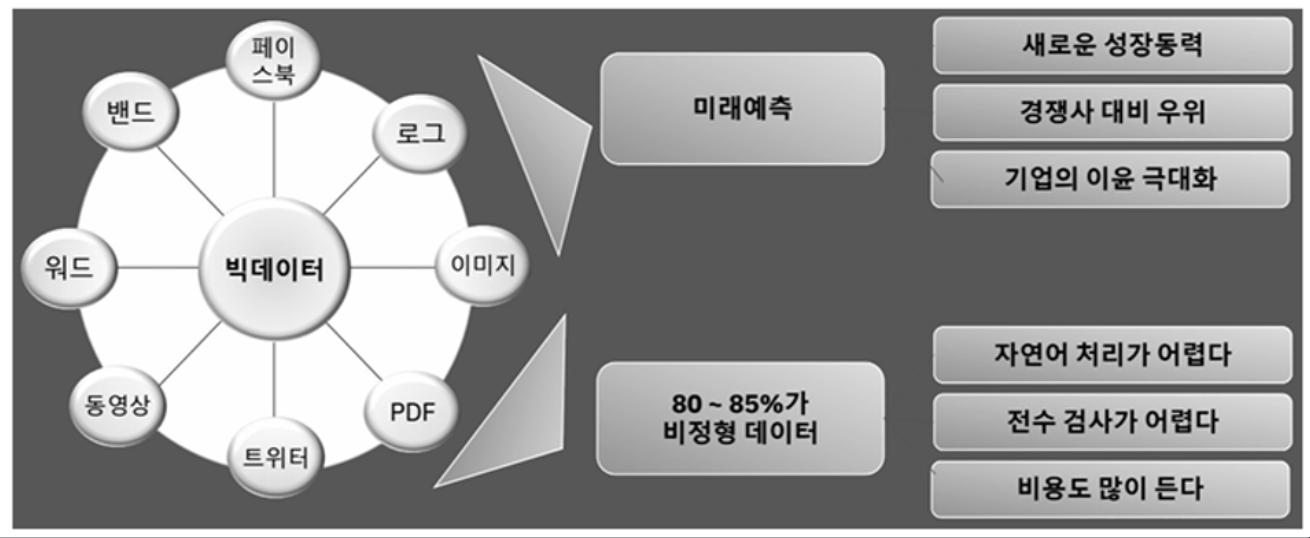
비정형 데이터의 중요성
- 비정형데이터란 그림이나, 영상, 문서처럼 구조화되지 않는 데이터
- 일정한 규격이나 형태를 지닌 숫자 데이터와 다리 형태와 구조가 다른 데이터
- 비정형데이터는 책, 잡지, 문서, 의료기록과 같은 텍스트 정보, 음성 정보, 영상 정보와 같은 전통적인 데이터 외에 이메일, 트위처, 블로그처럼 모바일 기기와 온라인에서 생성되는 데이터
텍스트마이닝
텍스트마이닝(Text Mining)
대규모 텍스트 형태의 비정형 데이터로부터 유용한 정보를 찾는 것
텍스트 마이닝을 영어사전 그대로 풀이하면,
"문서(Text)의 채굴(Mining)" 이다.
데이터 분석 관점에서 정의하면,
"텍스트 형태의 비정형 데이터로부터 새로운 고급 정보를 이끌어 내는 과정" 이다.
- 텍스트 마이닝은 텍스트를 이용하여 패턴이나 관꼐를 추출하고 그 안에서 의미 있는 정보나 가치를 발굴하여 해석하는 일련의 과정
- 텍스트 마이닝은 다양한 문서로부터 데이터를 획득해 이를 문서별 단어의 매트릭스로 만들어 추가 분석이나 데이터 마이닝 기법을 적용해 통찰을 얻거나 의사결정을 지원하는 방법
텍스트 분석 처리 프로세스
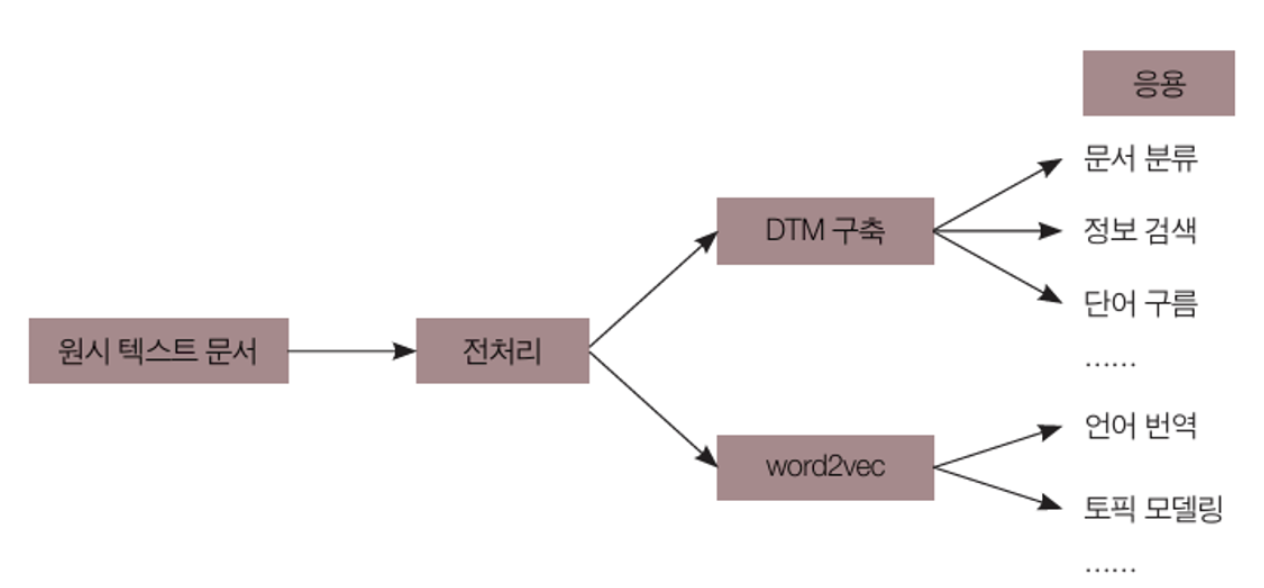
- Word2Vec는 Word to Vector 라는 이름에서 알 수 있듯이 단어(Word)를 컴퓨터가 이해할 수 있도록 수치화된 벡터(Vector)로 표현하는 기법 중 하나
- 데이터 수집 및 전처리
- 웹 크롤링
- 데이터 수집 키워드
- 데이터 전처리
- 빈도 분석
- 네트워크 및 CONCOR 분석
- N-gram 분석
- CONCOR 분석
전처리
Part-of-speech tagging
- 명사, 동사, 형용사 등 품사분석
- 한국어 텍스트는 Python의 Konlpy 활용
- 영어 텍스트는 NLTK 활용
Lemmatization(Tokenization)
- 단어의 의미단위 기본형 추출
불용어 및 특수 문자 제거
- 단어의 의미단위 기본형 추출
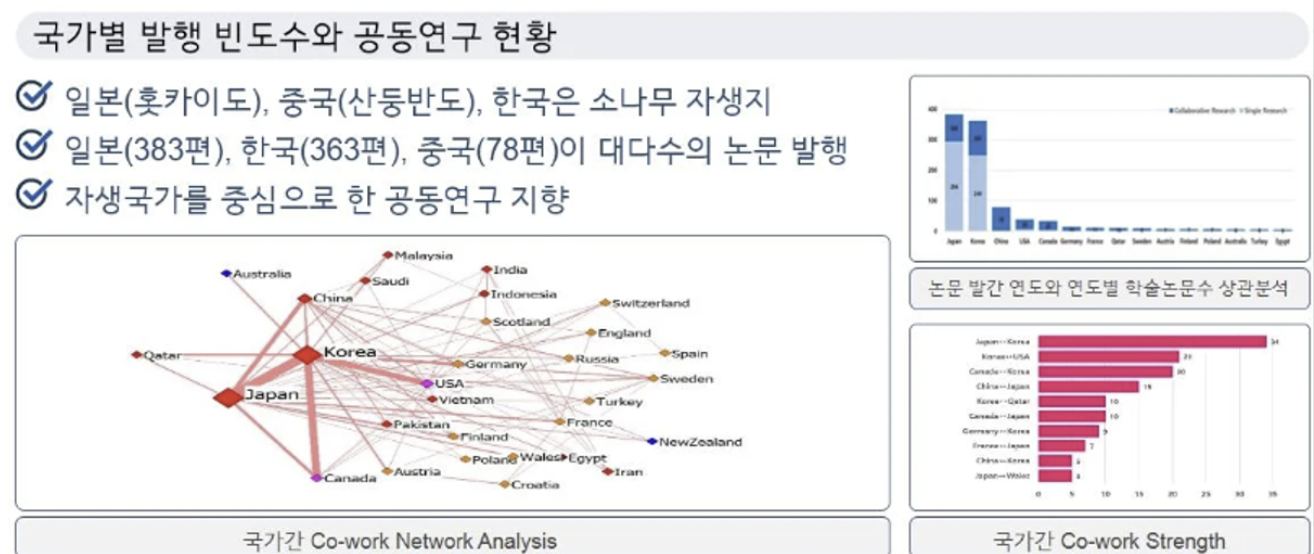
사례 #1
논문 발행수 빈도 분석
사례 #2
단어 빈도 분석

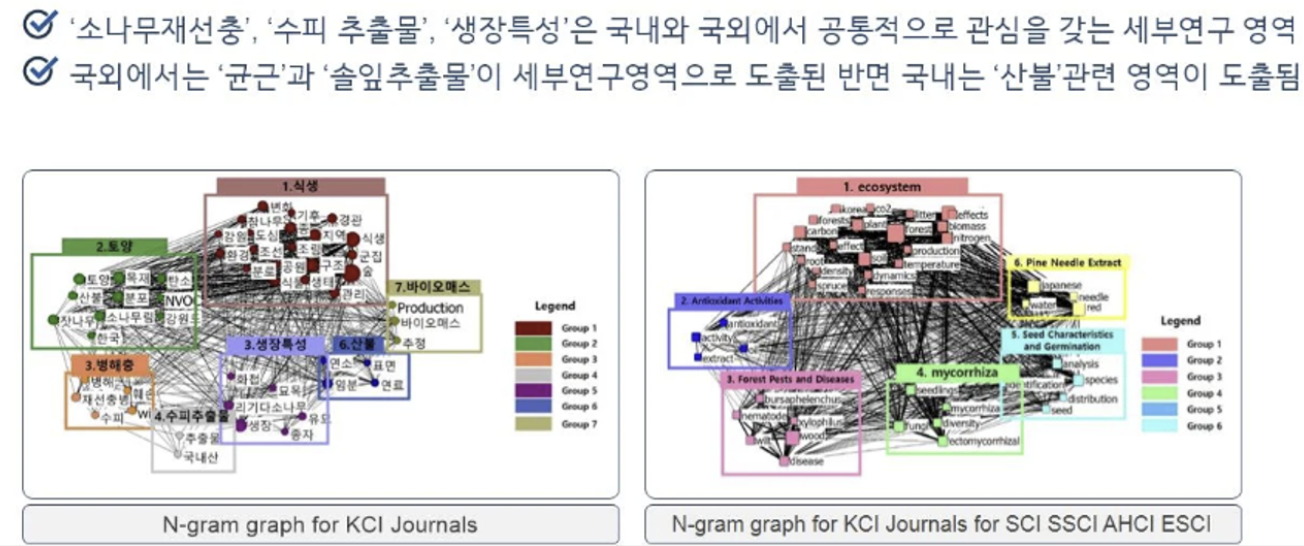
사례 #3
CONCOR 분석
2. 워드클라우드

실습하기
> install.packages("RCurl")
> library(RCurl)
> install.packages("XML")
> library(XML)
> t<-readLines('https://en.wikipedia.org/wiki/Data_science')
> d<-htmlParse(t,asText=TRUE)
> clean_doc<-xpathSApply(d, "//p",xmlValue)
> install.packages("tm")
> library(tm)
> install.packages("SnowballC")
> library(SnowballC)
> doc<-Corpus(VectorSource(clean_doc))
> inspect(doc)
> doc<-tm_map(doc,content_transformer(tolower))
> doc<-tm_map(doc,removeNumbers)
> doc<-tm_map(doc,removeWords,stopwords('english'))
> doc<-tm_map(doc,removePunctuation)
> doc<-tm_map(doc,stripWhitespace)
> dtm<-DocumentTermMatrix(doc)
> dtm(dtm)
> inspect(dtm)
> install.packages("wordcloud")
> library(wordcloud)
> m<-as.matrix(dtm)
> v<-sort(colSums(m),decreasing = TRUE)
> d<-data.frame(word=names(v),freq=v)
> wordcloud(words=d$word,freq=d$freq,min.freq=1,max.words=100,random.order=FALSE,rot.per=0.35)
> inspect(dtm)
> library(wordcloud)
> m<-as.matrix(dtm)
> v<-sort(colSums(m),decreasing=TRUE)
> d<-data.frame(word=names(v),freq=v)
> wordcloud(words=d$word,freq=d$freq,min,freq=1,max.words=100,random.order=FALSE,rot.pe$)
결과

3. 소셜네트워크 분석
소셜네트워크 생성
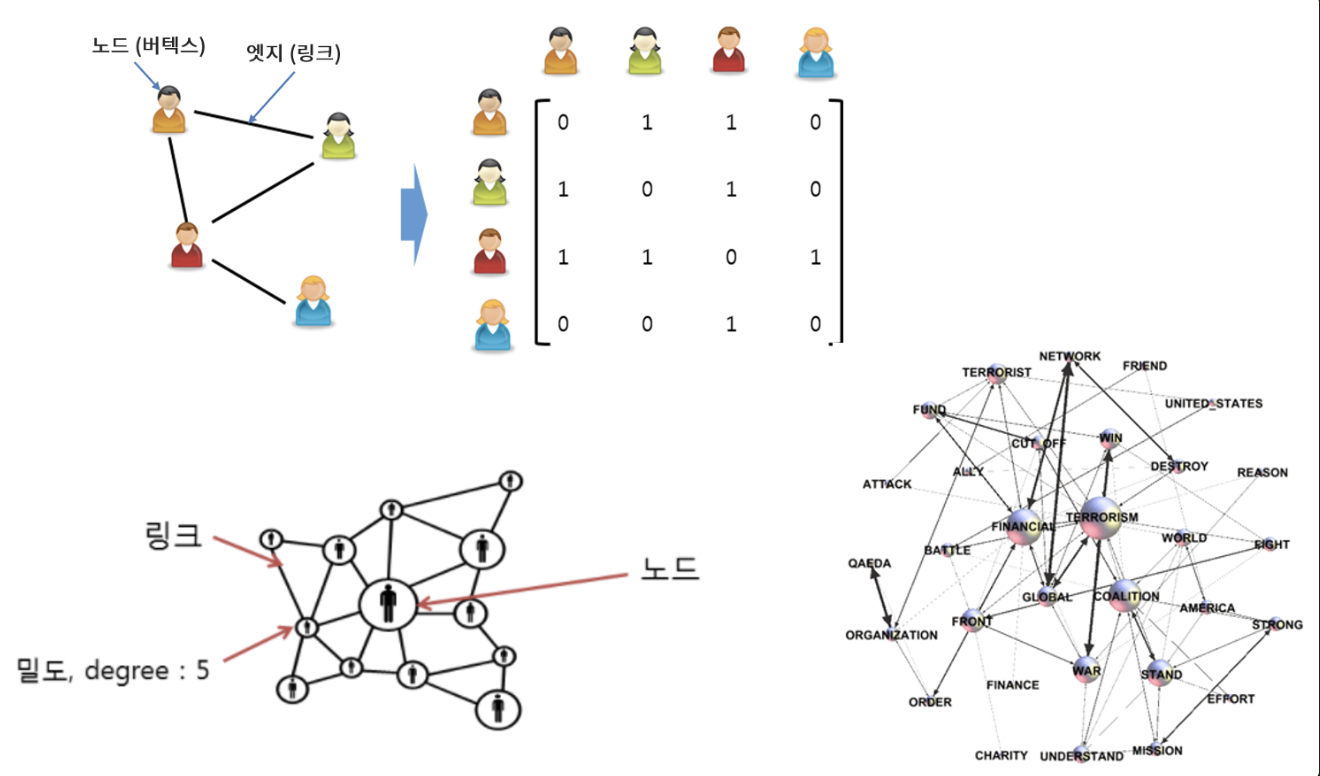
- row vector(행 벡터)
- column vector(열 벡터)
-> 행렬 벡터를 매트릭스 파일로 불러온다. -> 트래픽이 노드에 집중되있음 -> 분산 작업(로드 밸런싱 등) 진행
소셜네트워크 분석
- 개인과 집단들 간의 관계를 노드와 링크로서 모델링해 그것의 위상구조와 확산 및 진화과정을 계량적으로 분석하는 방법론
- 사회연결망에 대한 개념은 Jacob Mareno가 처음으로 [sociometry]에 발표
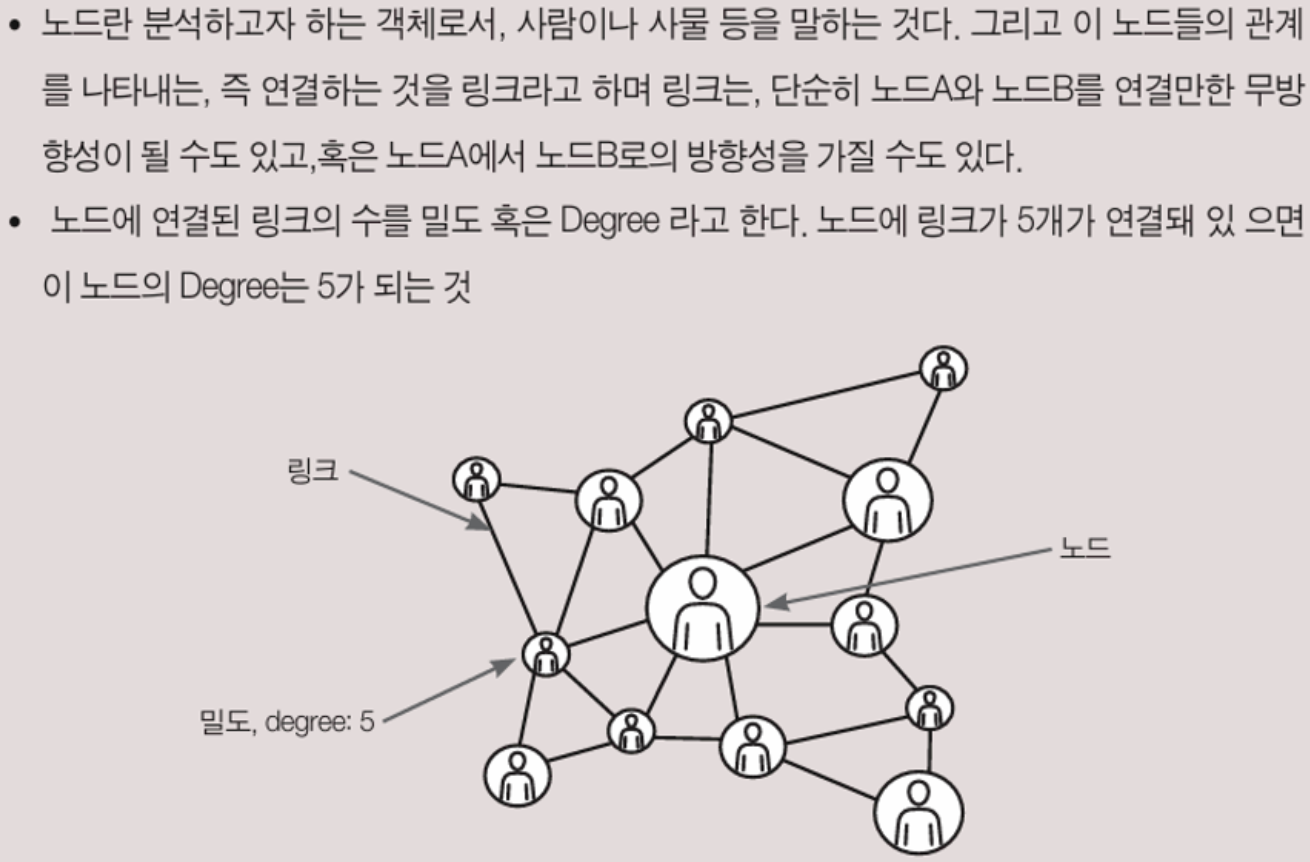
소셜네트워크 분석 기법
사회연결망 연구에서 많이 활용되고 있는 기법은 중심성(Centrality), 밀도(Density), 중심화(Centralization)이 있다. 이 중심성(Centrality) 방법에는 4가지가 존재.
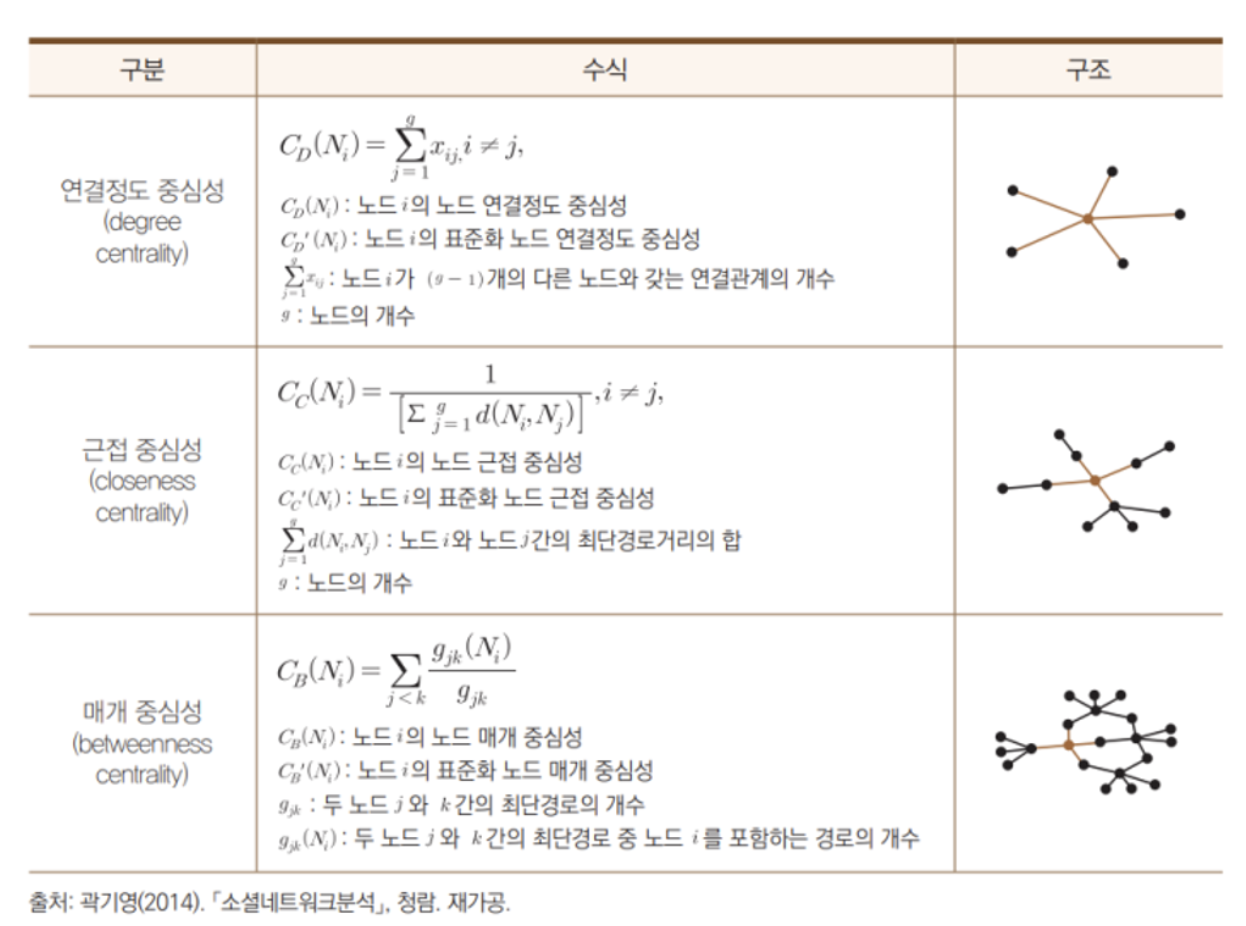
1. 연결정도 중심성(Degree Centrality)
- 한 노드에 직접적으로 연결된 노드들의 합으로 얻어짐. 한 노드에 얼마나 많은 노드들이 계를 맺고 있는지를 기준으로, 그 노드가 중심에 위치하는 정도를 계량화 한 것.
- 연결정도 중심성은 한 노드의 중심성을 측정하는 방법. 연결된 노드의 수가 많을수록 연결정도 중심성이 높아짐
2. 매개 중심성(Betweenness Centrality)
- 네트워크 내에서 한 노드가 담당하는 매개자 혹은 중재자 역할의 정도로 중심성을 측정하는 방법.
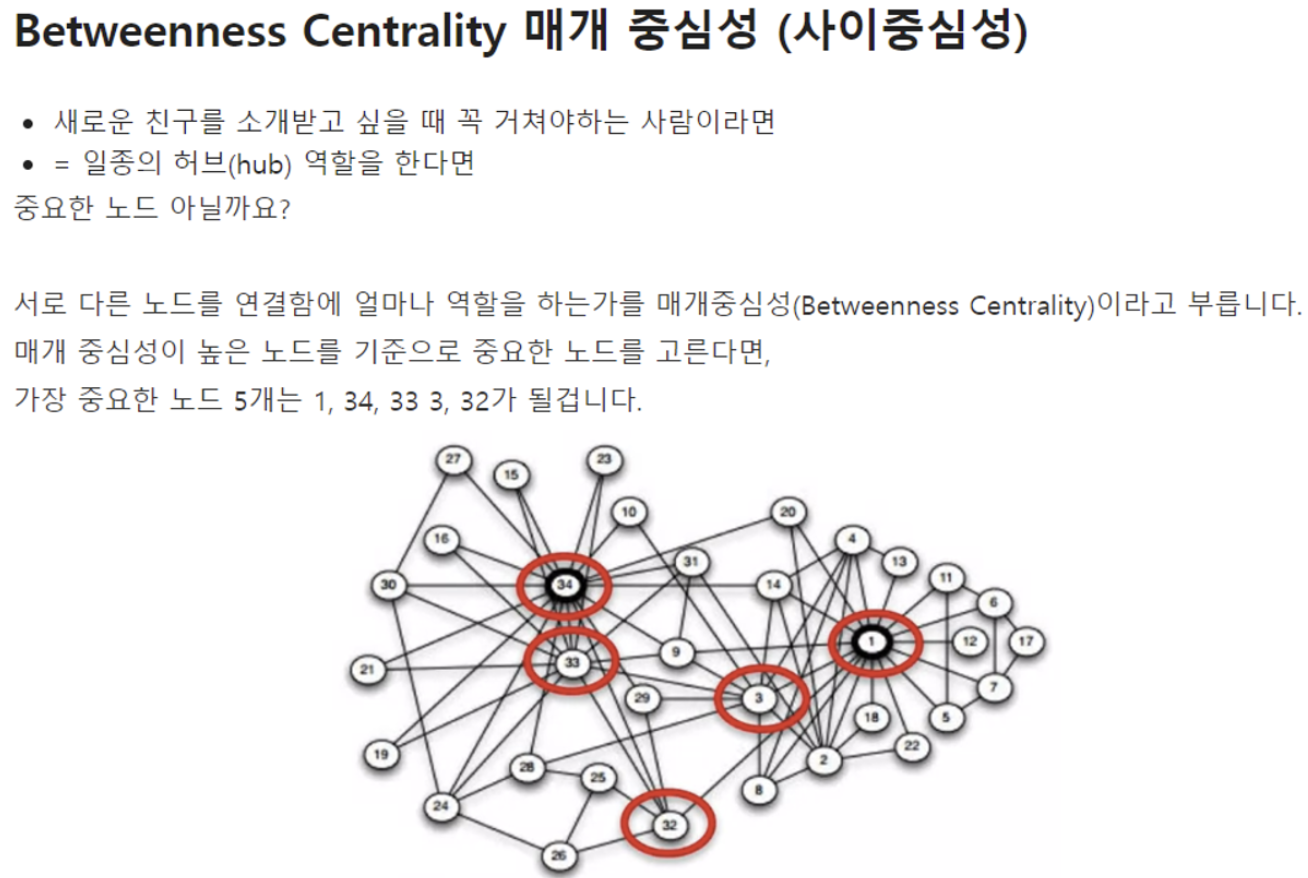
3. 근접중심성(Closeness Centrality)
- 각 노드 간의 거리를 근거로 중심성을 측정하는 방법, 연결정도 중심성과는 달리 간접적으로 연결된 모든 노드 간의 거리를 합산해 중심을 측정. 가장 짧은 경로로 모든 사람을 알게 되는 것이 근접 중심성. 근접중심성이 높을 수록 네트워크의 중앙에 위치
4. 위세 중심성(Eigenvector centrality)
- 연결된 노드의 중요성에 가중치를 둬 노드의 중심성을 측정하는 방법. 위세 중심성의 일반적인 형태는
보나시치 권력지수로 불리며, 자신의 연결정도 중심성으로부터 발생하는 영향력과 자신과 연결된 타인의 영향력을 합해 위세 중심성을 결정
각 분석 값 계산식
소셜네트워크 분석 사례
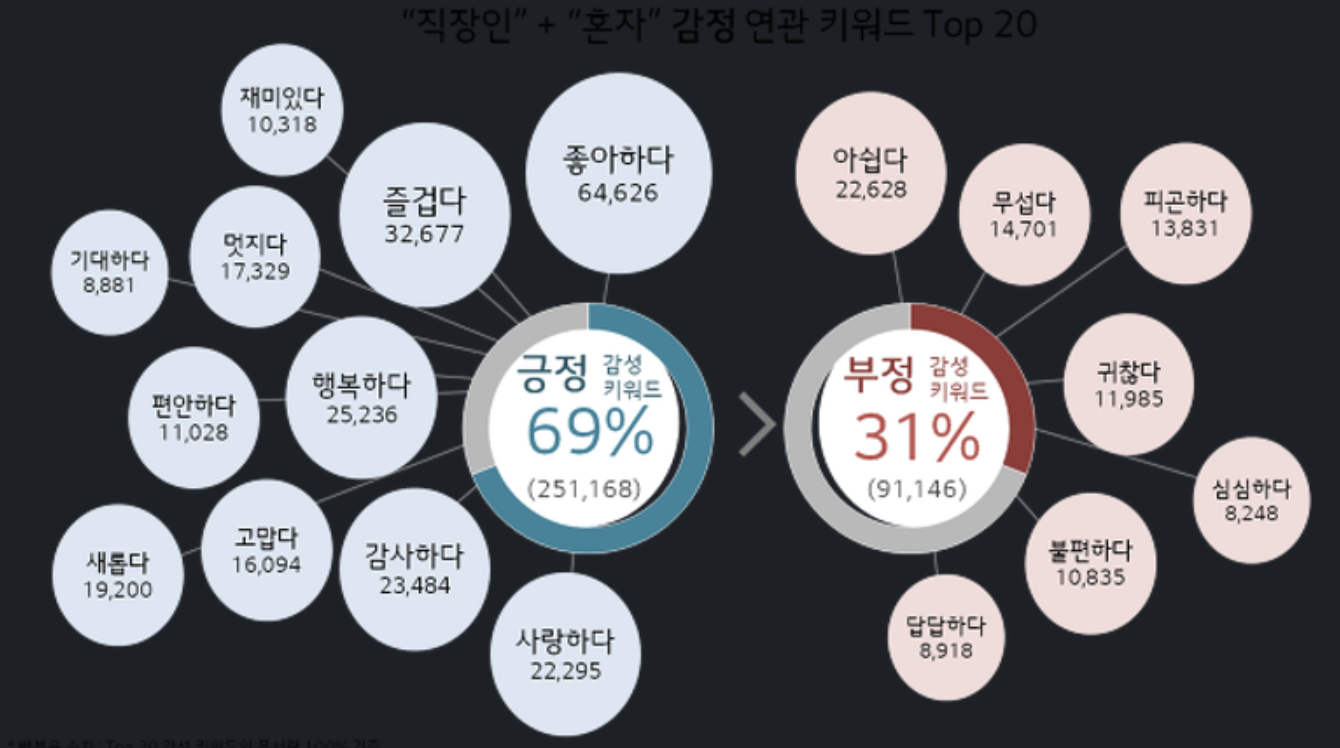
소셜네트워크 분석의 활용 및 해석
소셜 네트워크는 네트워크를 구성하여, 몇 개의 집단으로 구성되는지, 집단 간의 특징을 무엇이고 해당집단에서 영향력 있는 고객은 누구인지, 시간의 흐름과 고객 상태의 변화에 따라 다음에 누가 영향을 받는지를 기반으로 시각탐지, 상품추천 가입자 예측 등 활용
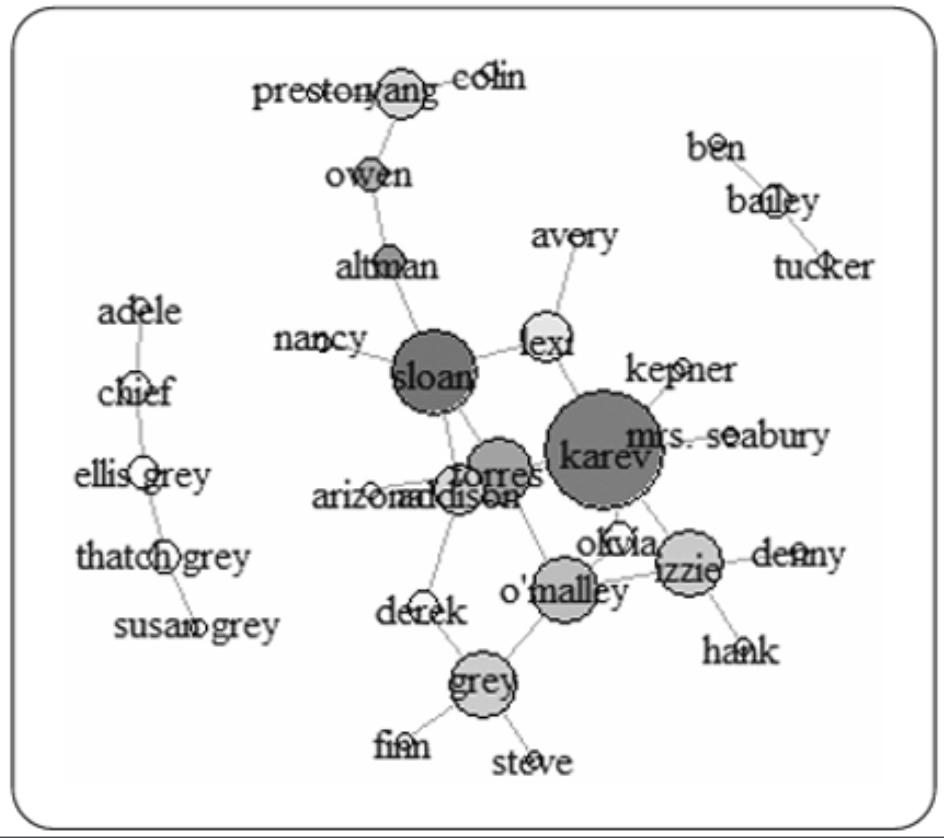
- 이웃한 노드는 서로 관련이 높은 집단
- 소셜 네트워크에서 그래프에서 이러한 집단을 커뮤니티라고 하며, 각 노드는 커뮤니티에서 역할이 정의
- 예를 들어 자신의 커뮤니티와 다른 커뮤니티에 모두 연결이 많은 것을
유력자(influ-encer), 여러 노드와 연결된 것은리더 지위(leader position), 커뮤니티와 커뮤니티를 연결하는 데 사용되는 노드는브릿지(bridge)역할을 하는 노드
NetMiner 를 활용한 시각화 체험
분석모습
https://youtu.be/aB8eLE5BgcI?feature=shared
다운로드
Free Trial - Free Trial - NetMiner
댓글남기기