3.빅데이터 통계기반 데이터분석
1. 통계기반 데이터 분석
빅데이터 분석 또한 분석 플랫폼을 적용해서 나온 결과값, 또는 시각화된 결과를 “해석”할 수 있어야 하는 것
2. 통계의 기초 및 통계량
기초적인 통계 개념(용어) 정리
1. 대표값:
분포의 중심위치를 나타내는 측정치
- 관찰된 자료들이 어느 곳에 가장 많이 모여있는가?, 즉 집중화 경향을 나타내는 값으로 평균, 중앙값, 최빈치, 사분위수 등이 있음
2. 산포도(흩어진 정도):
- 측정형 변수에 대한 분석에서 중앙 위치만 알고 있으면 전체에 대한 정보를 얻는데 한계가 있음
- 같은 평균을 같더라도 흩어진 정도에 따라 차이가 있으면 자료의 특성은 다름, 즉, 산포도가 클수록 폭이 넓고, 산포도가 작을 수록 분포의 흩어진 폭은 좁다.
3. 범위:
- 자료의 관측치 가운데 최대값과 최소값의 차이
4. 평균 절대 편차:
- 관측치들의 평균값으로 부터 떨어져 있는 거리
5. 분산, 표준편차:
- 분산: 데이터가 퍼져있는 상태, 분산이 ‘0’이면 모든 변량이 평균값에 집중, 분산이 크면 클 수록 변량이 평균에서 멀리 떨어져 있음
- 표준편차: 데이터가 평균 근처에 모여있는지? or 떨어져 있는지?
6. 변량:
- 점수, 시간 같은 여러자료를 수량으로 나타낸것 예) 92, 84, 37, 99, …
7. 모집단, 모집단특성( = 모수), 표본, 표본특성( = 통계량):
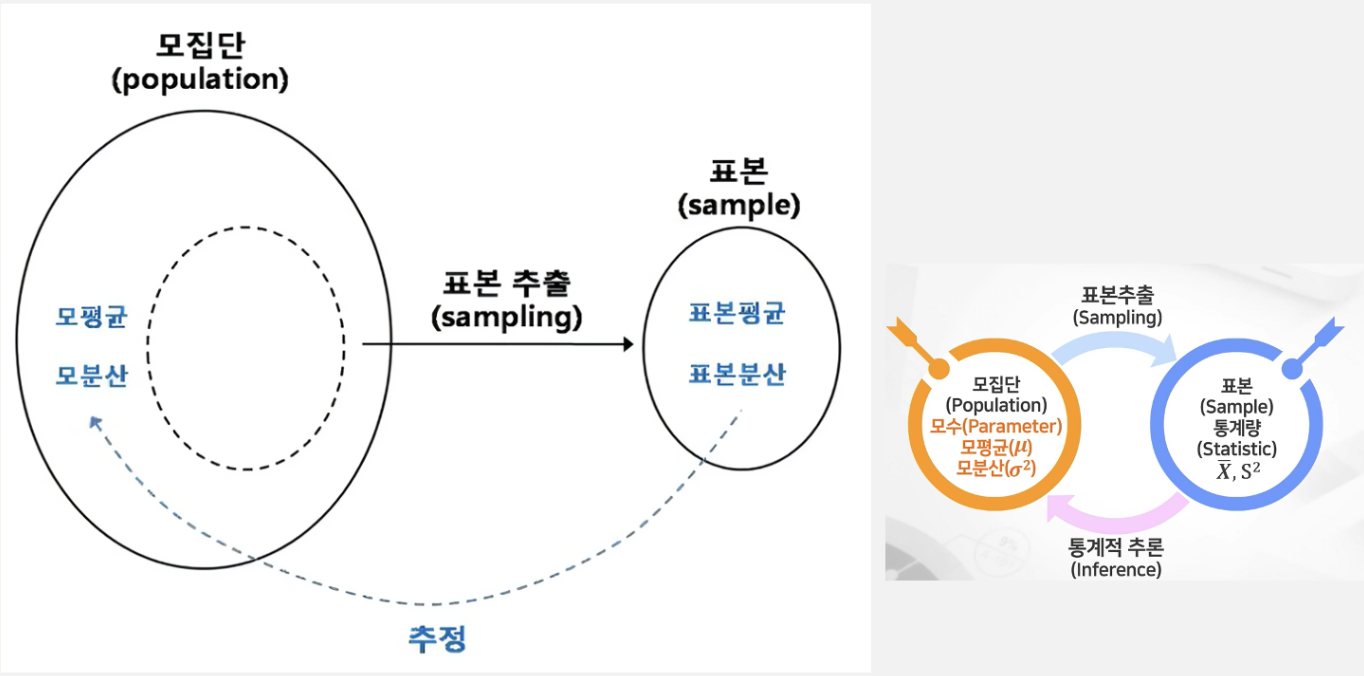
기술 통계 vs 추론통계
기술통계:
관측을 통해 얻은 데이터에서 그 데이터의 특징을 규명하기 위한 통계적 기법
- 분석의 초기 단계에서 데이터 분포의 특징을 파악하려는 목적으로 주로 산출
추론통계:
수집된 데이터를 기반으로 모집단위 특성을 추론하고 예측하는데 사용하는 통계적 기법
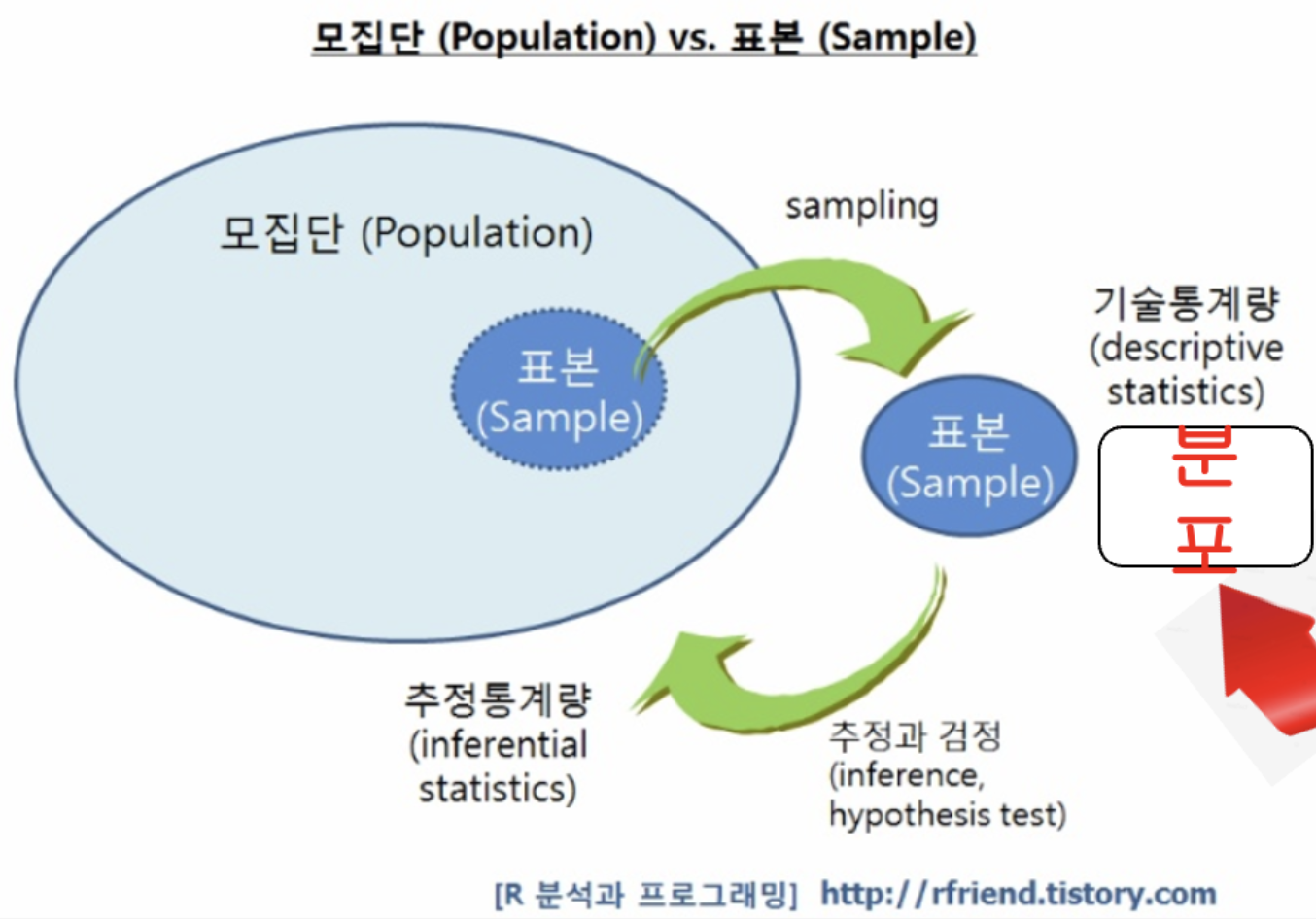
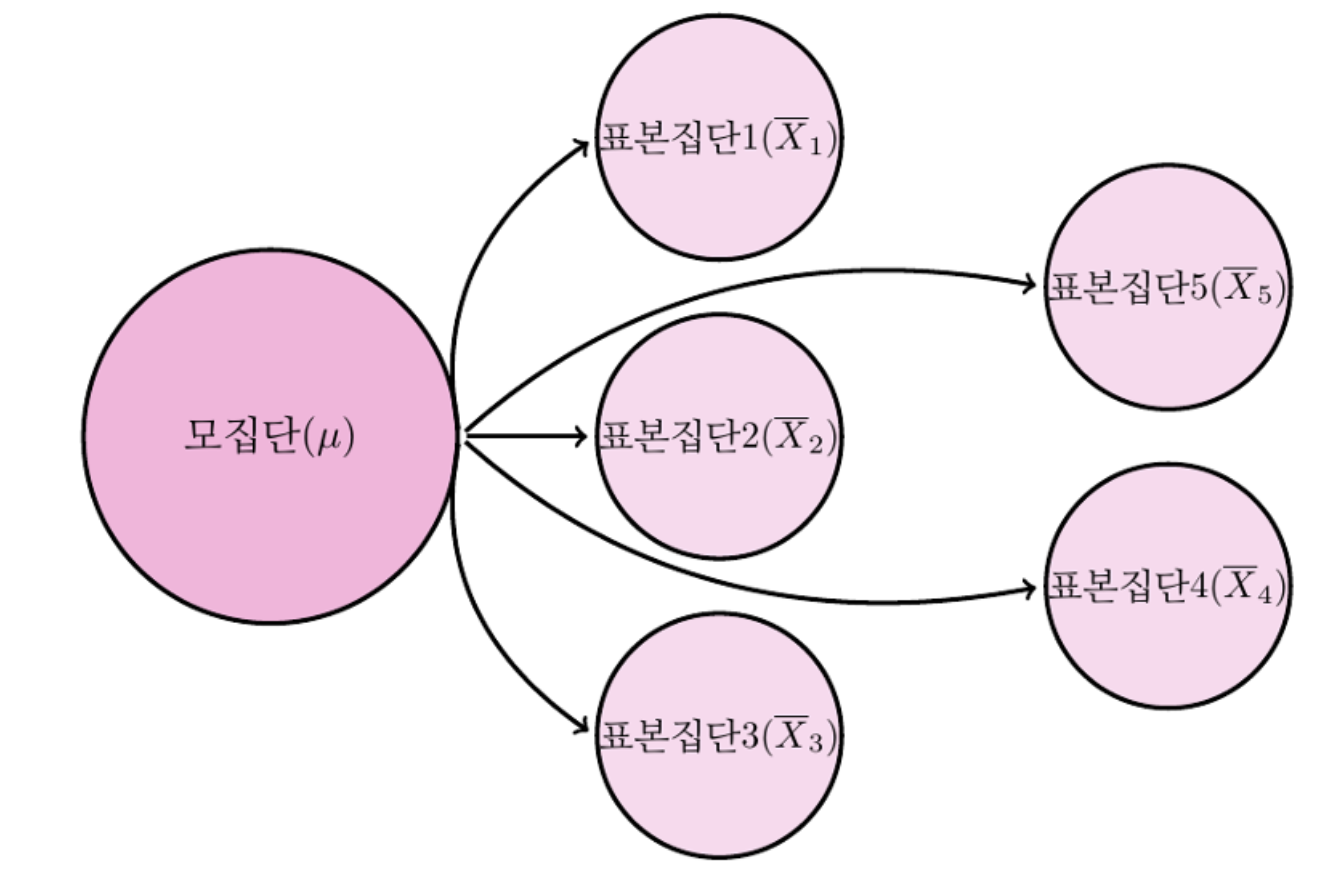
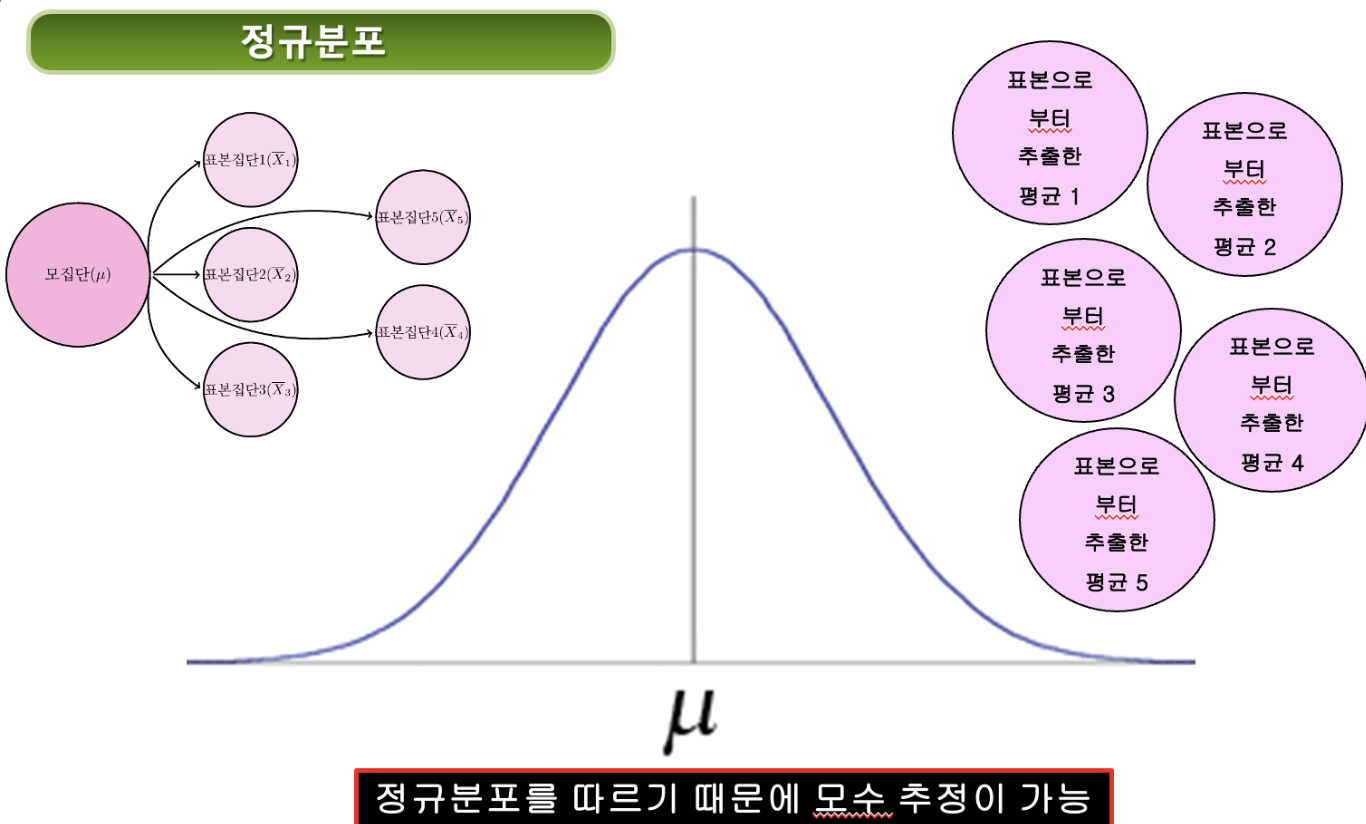
표본분포
주어진 모집단으로부터 크기 n의 확률분포를 수없이 반복하여 추출한 결과로 얻은 표본통계량의 확률분포
확률분포: 미래에 발생할 사건에 대해 확률을 나열한 것
표본분포의 종류
- 표본 분포는 이산확률 분포와 연속확률 분포의 2개의 종류로 구분
| 이항분포 | 정규분포 |
|---|---|
| 베르누이 시행 | 표준정규분포(z분포) |
| 포아송 분포 | t-분포 |
| 초기하 분포 | F-분포 |
| 기하 분포 | 카이제곱분포 |
| … | … |
정규분포
표준정규분포 vs t-분포
모집단이 정규분포를 따르지만 모표준편차를 알 수 없을 뿐 아니라 표본의 크기가 30개를 넘지 못하는 경우
- 평균: 0, 표준편차: 1
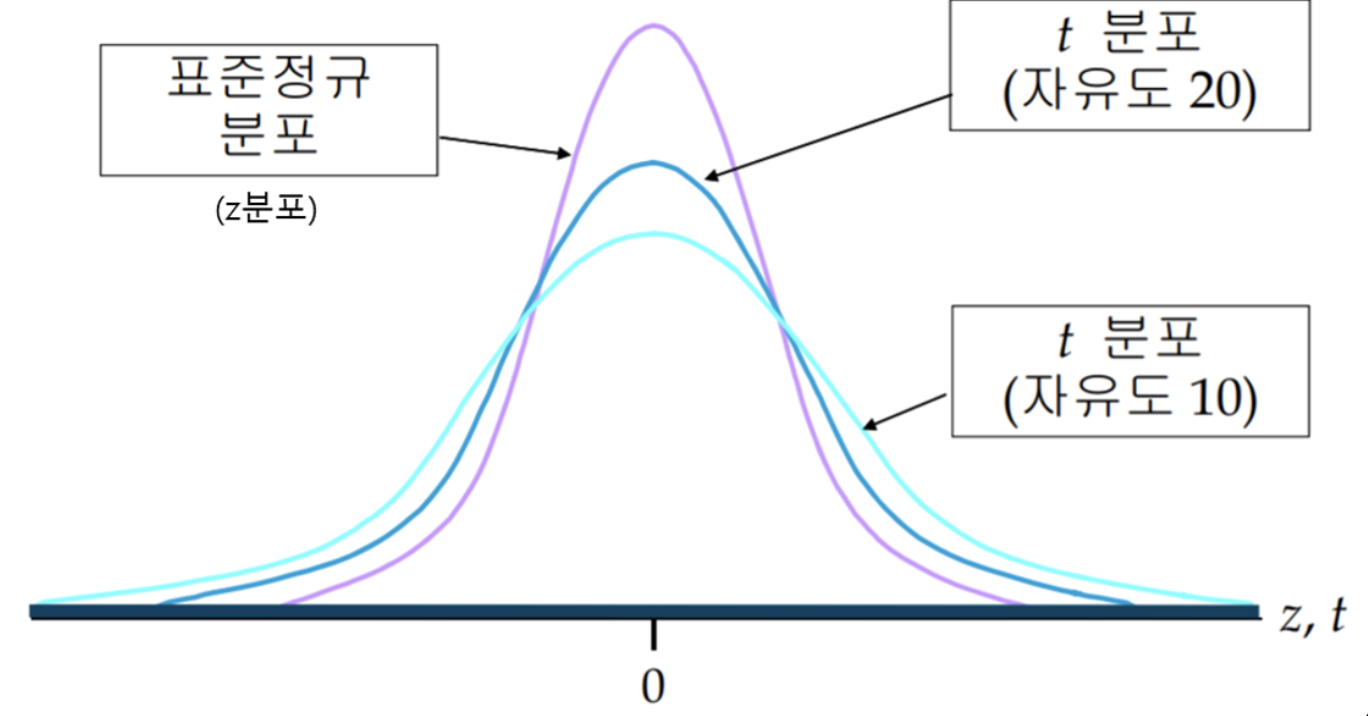
샘플이 크면 클 수록 평균 집중되고, 샘플이 작으면 작을 수록 평균에 근접하지 않는 값들이 많아짐. 따라서, 샘플이 많아야 확률적으로 정확도가 높아짐을 추정할 수 있음
3. 추론 통계
점추정:
가장 참이라고 여겨지는 하나의 모수의 값을 택하는 것, 즉 점추정은 ‘모수가 특정한 값일 것’ 이라고 추정하는 것
- 점추정치는 표본오차 때문에 모수와 일치하기 어려움. 오차를 없애려면 전수조사를 해야하는 데 현실적으로 불가능한 경우가 많음
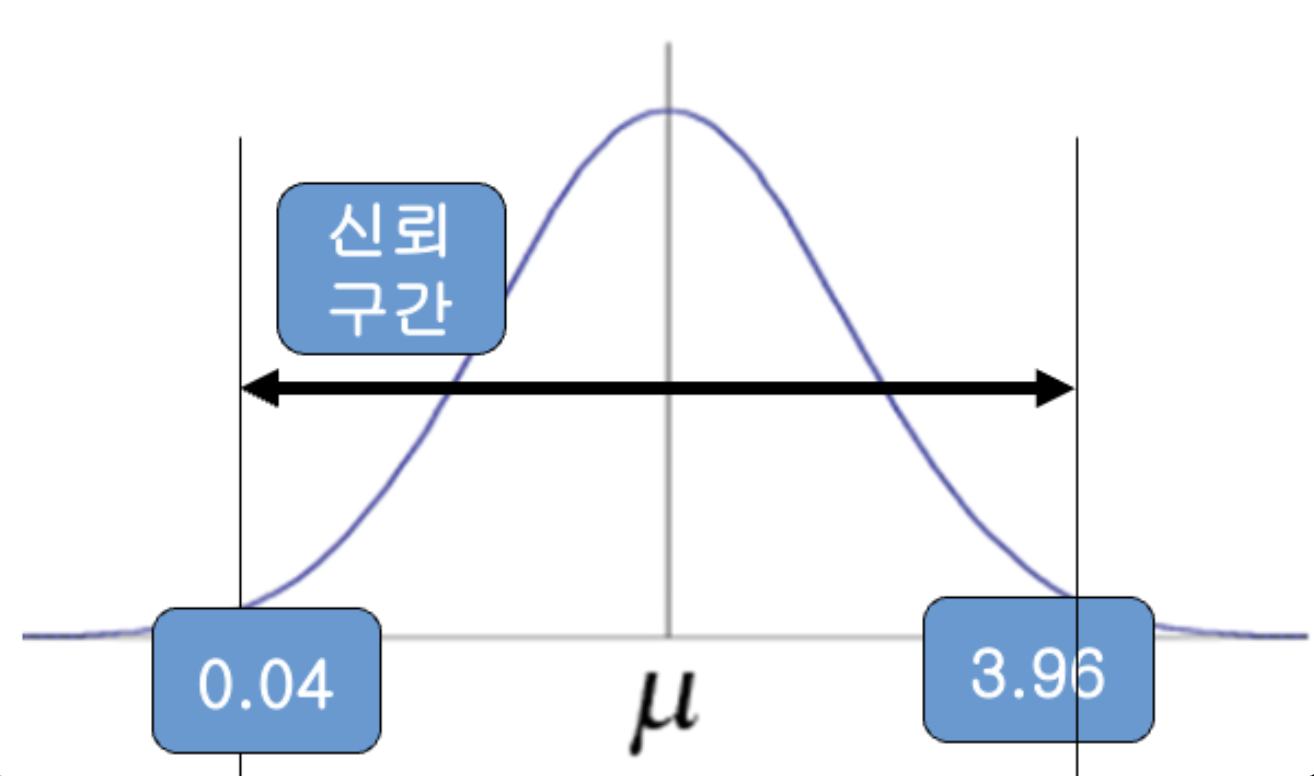
구간추정:
일정한 크기의 신뢰수준(신뢰도)으로 모수가 특정한 구간에 있을 것이라고 선언하는 것을 의미. 점추정치를 중심으로 하한부터 상한까지의 구간은 신뢰구간이라고 함.
-
신뢰수준(신뢰도): 신뢰수준 95%라 함은, 동일한 추정방법을 사용하여 신뢰구간을 100회 반복하여 추정한다면, 95회 정도는 동일한 결과가 나오는 것을 의미 -
신뢰구간: 일정한 구간을 제시하여 모수가 포함되었을 것이라고 제시한 구간,구간추정은 이 신뢰구간을 이용한 추정방법임. 구간추정에서 95% 신뢰구간이란 신뢰구간을 100회 반복하여 측정했을 때 95번은 그 구간내에 모평균이 포함된다는 의미
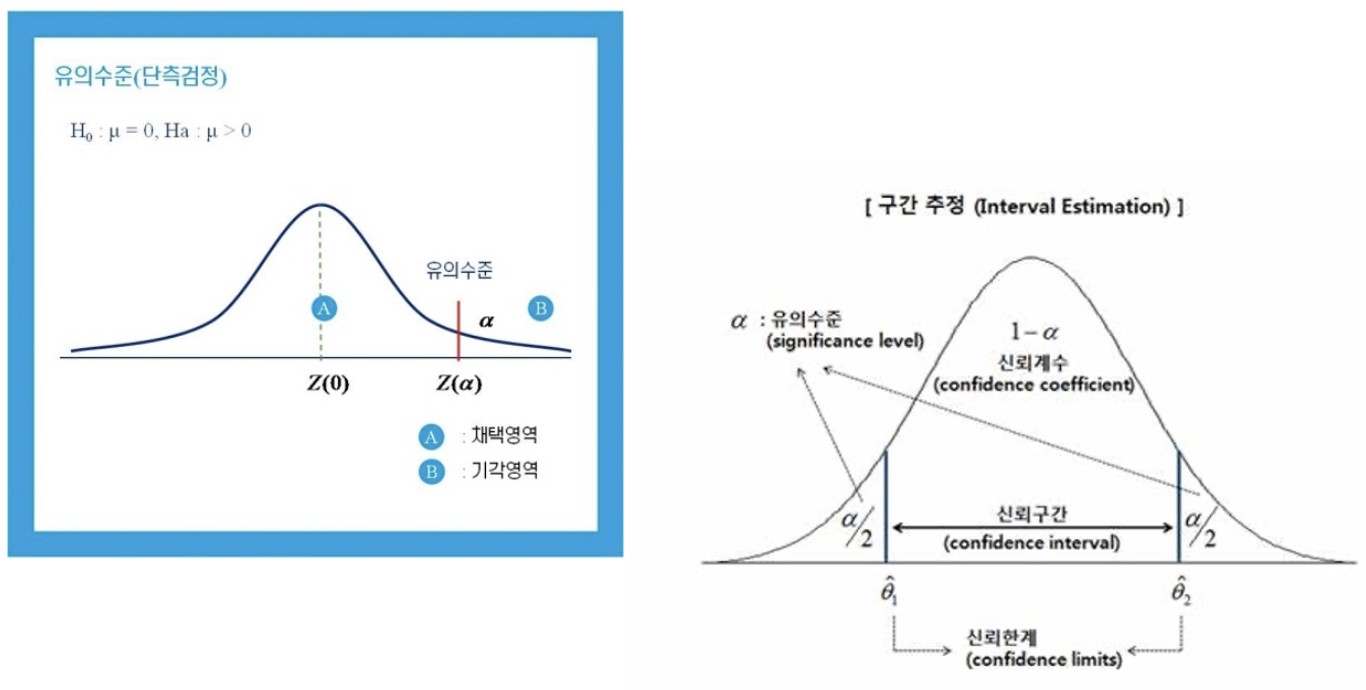
신뢰수준 vs 신뢰구간
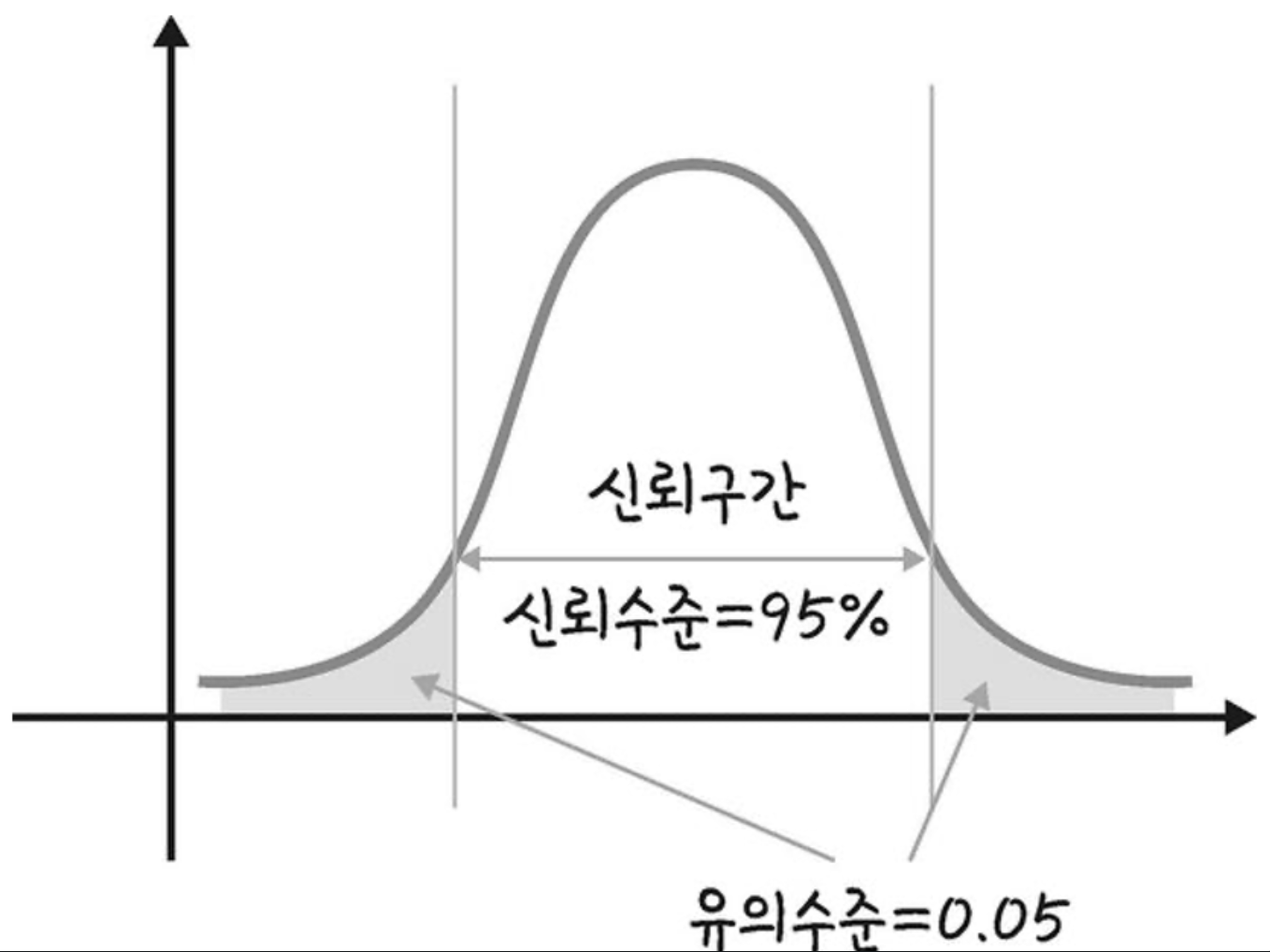
- 신뢰구간을 짧게할수록 정확률도 올라간다.
가설검정
가설
모수에 대한 잠정적인 주장 또는 가설
귀무가설(H0)
모집단의 특성에 대해 옳다고 제안하는 잠정적인 주장
대립가설(H1, 연구가설)
귀무가설의 주장이 틀렸다고 제안하는 가설, 귀무가설이 기각되면 채택되는 가설
유의수준(α)
가설을 기각 또는 채택하는 판단기준이 되는 것
가설검정
대상 집단의 특성량에 대하여 어떤 가설을 설정하고, 대상집단인 모집단으로부터 표본으로 가설을 검토하는 통계적 추론
P-value(p값)
P-value란 귀무가설이 진실이라는 가정하에 검정통계량이 표본으로부터 계산된 검정통계량의 값보다 더욱 멀어져 귀무가설을 기각시킬 확률을 의미
p-value < α이면 귀무가설(H0)을 기각
p-value > α이면 귀무가설(H0)을 채택
가설검정(1)
- 어떤 새로운 약물이 고혈압 환자의 혈압을 낮추는지 확인
귀무가설: 새로운 약물은 고혈압 환자의 혈압을 낮추지 않는다.대립가설(연구가설): 새로운 약물은 고혈압 환자의 혈압을 낮춘다.- 평균 혈압 변화와 해당 변화의 p-value(유의확률) 확인
유의 수준: 0.05(5%) 설정 -> 통계적으로 유의미한 결과를 얻기위해 95% 신뢰수준을 선택했음을 의미p-value: 0.03 -> α -> 실험결과가 우연에 의한것 보다 훨씬 더 드물다.- if p-value < 유의수준, 귀무가설 기각 -> 대립가설(연구가설) 채택
- 결과: 새로운 약물은 고혈압 환자의 혈압을 낮춘다.
가설검정(2)
- 학업 성취도와 수면패턴 사이의 관계
- 학생들의 수면 패턴이 학업 성취도에 어떤 영향을 미치는가?
귀무가설: 학생들의 수면 패턴과 성취도 사이에 유의미한 관련성이 없다.대립가설(연구가설): 학생들의 수면 패턴과 성취도 사이에 유의미한 관련성이 있다.- 연구자는 학생들을 대상으로 조사나 설문조사를 하여 수면 패턴(수면시간, 수면 품질)과 학업성취도(성적 등)에 관한 데이터를 수집한다. 연구자는 데이터를 상관분석이나회귀분석을 통해 수면 패턴과 학업 성취도 사이의 관계를 측정해 볼 수 있다. 연구자는유의 수준을 0.05로 설정하고, 결과의 통계적 유의성을 평가한다. 분석결과 수면패턴과 학업 성취도 사이의 상관계수나 회귀계수에 해당하는 p-value를 계산, p-value가 유의수준 0.05보다 작다면, 귀무가설은 기각되고 대립가설이 채택된다. 따라서, 연구자는 수면패턴과 학업성적 사이 유의미한 관련성이 있다는 결론을 내릴 수 있다.
댓글남기기